이번 글에서는 R에서 파일을 입/출력하는 방법에 대해 살펴보겠습니다.
우리는 보통 데이터를 다룰때 엑셀을 많이 쓰곤 합니다.
근데 이 데이터들을 R에서 일일이 입력해줄수 없으니 함수를 써야겠죠.
그래서 R에서 지원하는 함수들을 이용해 자료를 간단히 R에서의 데이터 프레임으로 전환시킬수 있습니다.
# file
# the name of the file which the data are to be read from.
# Each row of the table appears as one line of the file.
# If it does not contain an absolute path,
# the file name is relative to the current working directory, getwd().
# Tilde-expansion is performed where supported.
# This can be a compressed file (see file).
# Alternatively, file can be a readable text-mode connection
# (which will be opened for reading if necessary,
# and if so closed (and hence destroyed) at the end of the function call).
# (If stdin() is used, the prompts for lines may be somewhat confusing.
# Terminate input with a blank line or an EOF signal,
# Ctrl-D on Unix and Ctrl-Z on Windows.
# Any pushback on stdin() will be cleared before return.)
# file can also be a complete URL.
# (For the supported URL schemes, see the ‘URLs’ section of the help for url.)
# 읽을 파일입니다.
# 현재 폴더 위치에서 (getwd()명령어로 볼수 있습니다) 읽을 파일명을 입력하시면 됩니다.
# 혹은 절대 경로기준으로 설정하셔도 됩니다.
# 기본 폴더 위치 세팅 방법은 밑에서 다루겠습니다.
# header
# a logical value indicating whether the file contains the names
# of the variables as its first line.
# If missing, the value is determined from the file format:
# header is set to TRUE if and only if the first row contains
# one fewer field than the number of columns.
# 읽을 파일에 헤더가 있음을 가정하는 인자입니다
# 예를 들어 header=TRUE로 설정할 경우 읽을 데이터의 첫번째 행을 헤더로 간주하고 데이터 프레임에
# 자동으로 세팅해줍니다. 기본값은 FALSE입니다.
# sep
# the field separator character.
# Values on each line of the file are separated by this character.
# If sep = "" (the default for read.table) the separator is ‘white space’,
# that is one or more spaces, tabs, newlines or carriage returns.
# 문자와 문자 사이를 어떻게 구분할지 정해주는 인자입니다.
# 기본값은 ""이고 ""을 사용할 경우 하나 이상의 공백, 탭, 새로운 행 등으로 구분합니다.
# 일부 인자는 생략했습니다.
read.table(file, header = FALSE, sep = "", ...)
read.table("파일 명", sep="구분자", header=TRUE/FALSE) 형식으로 사용하시면 됩니다.

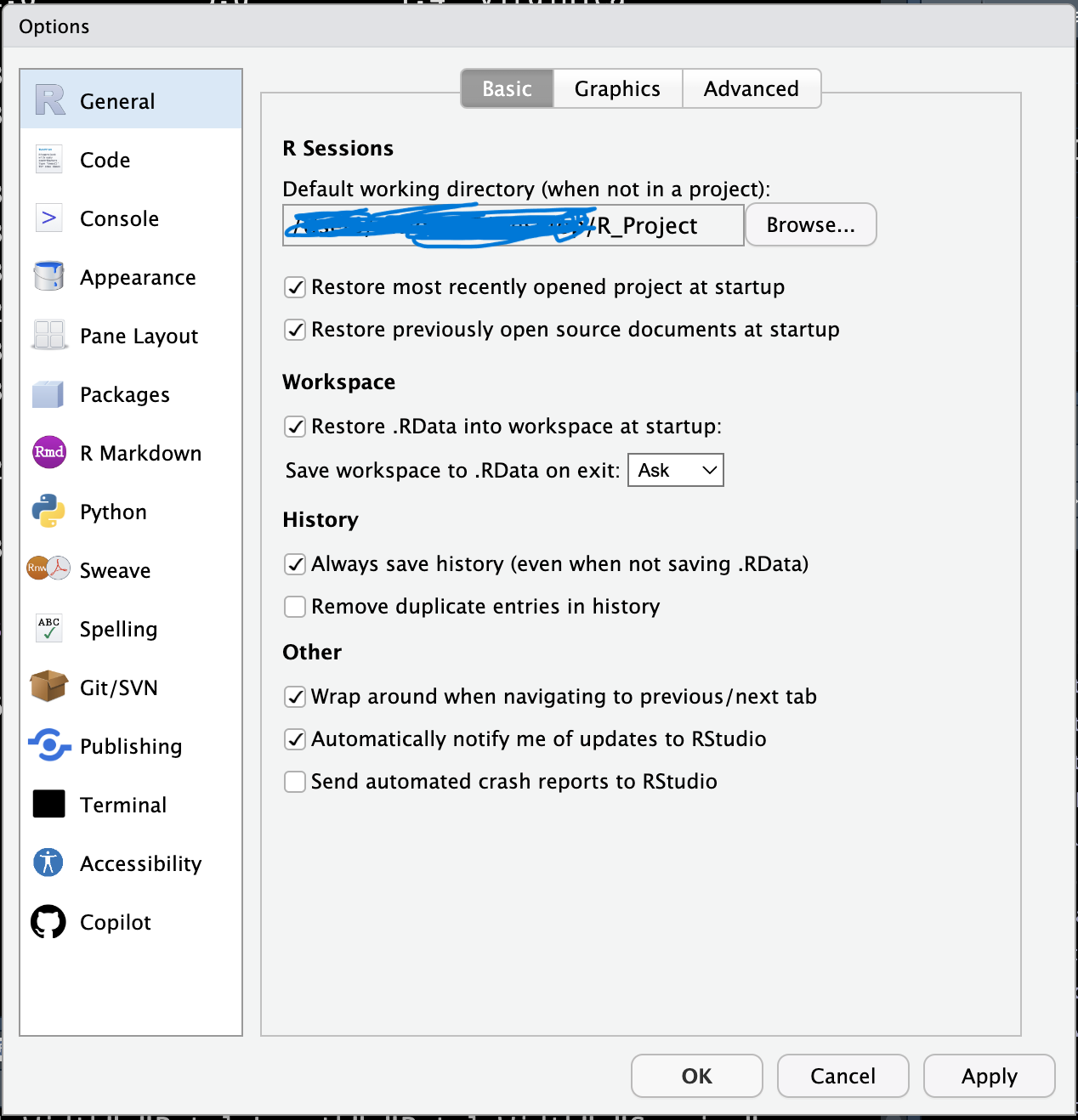
그리고 현재 폴더 위치를 세팅하는 방법은..
상단에서 Edit버튼을 누르고 탭이 열리면 Preferences를 눌러줍니다
그러면 3번째 화면이 뜰텐데 여기서 Browse버튼을 눌러주고 현재 폴더 위치를 세팅해주면 됩니다.


입력이 되면 쓰는것도 가능해야겠죠?
그래서 R에는 파일을 작성해주는 write.table이라는 함수도 있습니다.
# x
# the object to be written, preferably a matrix or data frame.
# If not, it is attempted to coerce x to a data frame.
# 매트릭스와 데이터 프레임을 파일로 작성할수 있습니다.
# 많약 매트릭스와 데이터 프레임이 아닐 경우 강제로 데이터프레임화 시켜서 파일을 작성합니다.
# file
# either a character string naming a file or a connection open for writing.
# "" indicates output to the console.
# 작성할 파일의 파일명입니다.
# sep
# the field separator string.
# Values within each row of x are separated by this string.
# 행들의 값을 구분해주는 문자입니다.
# 기본값은 " "입니다.
# 일부 인자는 생략했습니다.
write.table(x, file = "", sep = " ", ...)
아마 쓸일이 많지는 않겠지만.. 어떻게 쓰는거냐면..
이렇게 쓰면 됩니다.

위에서 작성한 mtcars.txt를 읽어볼까요?
읽었을때 다음과 같이 나오시는것을 보실수 있습니다.

그리고 추가로 엑셀 데이터를 편하게 읽고 작성할수 있는 라이브러리가 있습니다.
바로 xlsx라는 패키지인데요.
패키지를 다운받고 사용을 하게 해준다음에 read.xlsx, write.xlsx를 보게 되면.. 다음과 같습니다
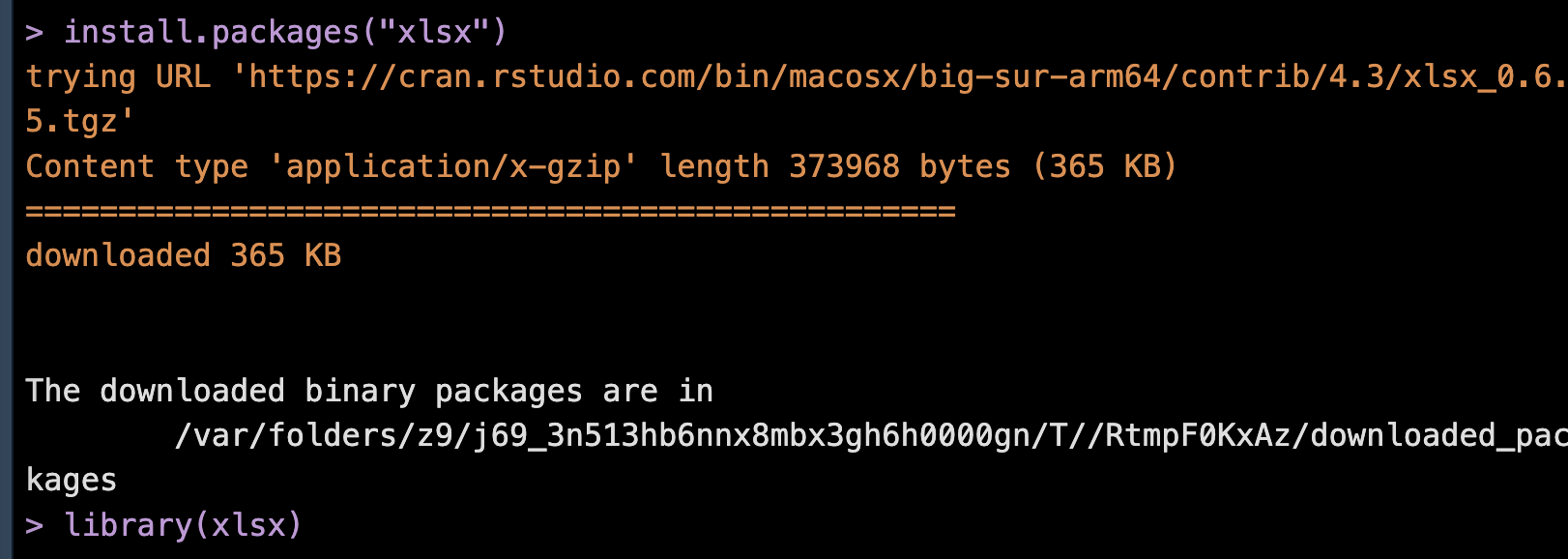
read.xlsx
# file
# the path to the file to read.
# 읽을 파일입니다.
# sheetIndex
# a number representing the sheet index in the workbook.
# 엑셀 시트 번호입니다.
# sheetName
# a character string with the sheet name.
# 엑셀 시트 이름입니다.
# rowIndex
# a numeric vector indicating the rows you want to extract.
# If NULL, all rows found will be extracted, unless startRow or endRow are specified.
# 값을 추출할 행입니다. 만약 NULL일 경우 값이 들어있는 모든 행을 추출합니다.
# startRow
# a number specifying the index of starting row.
# For read.xlsx this argument is active only if rowIndex is NULL.
# 추출을 시작할 행입니다. rowIndex가 NULL일 경우에만 이 값을 사용합니다.
# endRow
# a number specifying the index of the last row to pull.
# If NULL, read all the rows in the sheet.
# For read.xlsx this argument is active only if rowIndex is NULL.
# 추출을 마칠 행입니다. NULL일 경우 시트의 모든 행을 읽습니다.
# 그리고 rowIndex가 NULL일 경우에만 이 값을 사용합니다.
# colIndex
# a numeric vector indicating the cols you want to extract.
# If NULL, all columns found will be extracted.
# 값을 추출할 열입니다. 만약 NULL일 경우 값이 들어있는 모든 열을 추출합니다.
# as.data.frame
# a logical value indicating if the result should be coerced into a data.frame.
# If FALSE, the result is a list with one element for each column.
# 추출한 데이터를 데이터프레임으로 변환할지 묻는 인자입니다.
# 만약 FALSE일 경우 추출한 데이터는 리스트형 변수로 변환됩니다.
# 일부 인자는 생략했습니다.
read.xlsx(
file,
sheetIndex,
sheetName = NULL,
rowIndex = NULL,
startRow = NULL,
endRow = NULL,
colIndex = NULL,
as.data.frame = TRUE,
...
)
write.xlsx
# x
# a data.frame to write to the workbook.
# 엑셀 데이터를 만들 데이터 프레임입니다.
# file
# the path to the output file.
# 작성할 파일의 파일명입니다.
# sheetName
# a character string with the sheet name.
# 작성할 엑셀파일의 엑셀시트 이름입니다.
# 일부 인자는 생략했습니다.
write.xlsx(
x,
file,
sheetName = "Sheet1",
...
)
read.xlsx와 write.xlsx도 각각 read.table, write.table함수와 비슷하게 사용하실수 있습니다.
이만 글을 마치도록 하겠습니다
긴 글 봐주셔서 감사합니다

'Dev > R' 카테고리의 다른 글
| [R] 데이터 프레임을 다루는 함수 (1) | 2023.12.26 |
|---|---|
| [R] 데이터 프레임 (0) | 2023.12.24 |
| [R] 기본 내장 함수 (1) | 2023.12.23 |